
finmath lib cuda extensions
Vector class (RandomVariable) running on GPUs using CUDA.
Enabling finmath lib with Cuda via jcuda. - Running finmath lib models on a GPU.
The finmath lib cuda extensions provide a Cuda implementation of the finmath lib interfaces RandomVariable and BrownianMotion compatible with finmath lib 5.1 or later (tested on GRID GPU Kepler GK105, GeForce GTX 1080, GeForce GT 750M.
For OpenCL support see finmath-lib-opencl-extensions.
Performance Characteristics
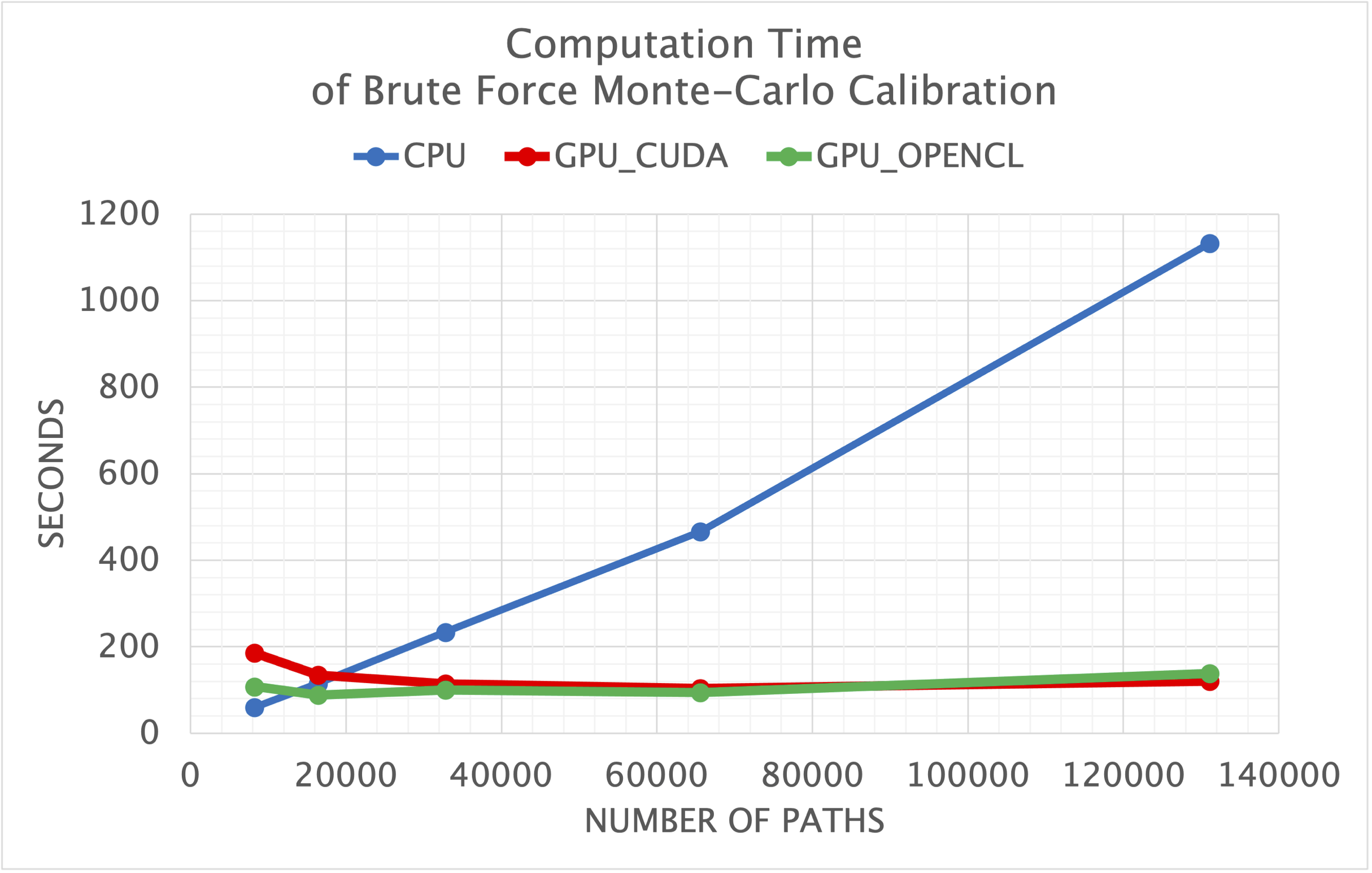
The current implementation uses very small CUDA kernels which affects the performance. This may be optimized quite straight forwardly in future versions. This implies a specific performance characteristic: the CUDA communication overhead constitutes a certain amount of “fixed costs”. Depending on GPU and CPU specifics the performance is at par for Monte Carlo simulations with 5000 paths. However, for larger number of paths, the CPU scales linear, while the GPU show almost no change. That is, For a Monte-Carlo simulation with 50000 paths, the GPU is 10 times faster than the CPU. For 100000 paths, the GPU is 20 times faster than the CPU.
Limitations
The main limitation is GPU memory. RandomVariable objects are held on the GPU and keept as long as they are referenced. Since multiple processes may aquire GPU memory, it may be less clear how much GPU memory is available. Larger Monte-Carlo simulations may require 12 GB or more of GPU memory.
Another aspect that may affect the performance is the CUDA implementation.
Interfaces for which CUDA Implementations are Provided
RandomVariable
A RandomVariableCudaFactory is provided, which can be injected in any finmath lib model/algorithm using a random variable factory to construct RandomVariable objects.
Objects created from this factory or from objects created from this factory perform their calculation on the CUDA device (GPU).
The implementation supports type priorities (see http://ssrn.com/abstract=3246127 ) and the default priority of RandomVariableCuda is 20. For example: operators involving CPU and GPU vectors will result in GPU vectors.
The RandomVariableCudaFactory can be combined with algorithmic differentiation AAD wrappers, for example RandomVariableDifferentiableAAD, to allow algorithmic differentiation together with calculations performed on the GPU. For the type priority: objects allowing for algorithmic differentiation (AAD) have higher priority, AAD on GPU has higher priority than AAD on CPU.
BrownianMotion
In addition, objects of type BrownianMotion are also taking the role of a factory for objects of type RandomVariable. Thus, injecting the BrownianMotionCuda into classes consuming a BrownianMotion will result in finmath-lib models performing their calculations on the GPU - seamlessly.
Distribution
finmath-lib-cuda-extensions is distributed through the central Maven repository. It’s coordinates are:
<groupId>net.finmath</groupId> <artifactId>finmath-lib-cuda-extensions</artifactId> <version>5.1.3</version>
The project is currently build for Cuda 10.2. For other Cuda versions use the Maven command line property cuda.version set to one of 8.0, 9.2, 10.0, 10.1, 10.2 and the Maven classifyer cuda-${cuda.version}.
Example
Create a vector of floats on the GPU device
RandomVariable randomVariable = new RandomVariableCuda(new float[] {-4.0f, -2.0f, 0.0f, 2.0f, 4.0f} );
perform some calculations (still on the GPU device)
randomVariable = randomVariable.add(4.0); randomVariable = randomVariable.div(2.0);
perform a reduction on the GPU device
double average = randomVariable.getAverage();
or get the result vector (to the host)
double[] result = randomVariable.getRealizations();
(note: the result is always double, since different implementation may support float or double on the device).
RandomVariableFactory
A better approach is to use a RandomVariableFactory instead of a constructor. You may then write your program in terms of the RandomVariableFactory interface:
RandomVariableFactory randomVariableFactory = new RandomVariableCudaFactory();
and then
RandomVariable randomVariable = randomVariableFactory.createRandomVariable(new float[] {-4.0f, -2.0f, 0.0f, 2.0f, 4.0f} );
If you write your code in terms of the RandomVariableFactory interface you may easily switch your implementations by using one of the following factories:
RandomVariableCudaFactory- CUDA vectors running on an CUDA device (GPU).RandomVariableFromArrayFactory- Java floating point array (single or double precision).RandomVariableDifferentiableAADFactory- Endowing any of the above with adjoint algorithmic differentiation.
Installation / Build
Binary distribution is available via Maven central.
You have to have NVIDIA Cuda 10.1 installed. The Maven configuration comes with profiles for Cuda 8.0, 9.2, 10.0 and 10.1. If you like to use a different version, you can try to switch the JCuda version by setting the property cuda.version on the Maven command line.
To build the project yourself and run the unit tests from the source repository:
Obtain the finmath-lib-cuda-extensions source
git clone https://github.com/finmath/finmath-lib-cuda-extensions.git cd finmath-lib-cuda-extensions
…then build the code.
mvn clean package
This will build the version using Cuda 10.2. For Cuda 10.1 use
mvn -Dcuda.version=10.1 clean package
If everything goes well, you will see unit test run. Note that some of the tests may fail if the device (GPU) has not enough memory.
Trying more
You may turn on logging using -Djava.util.logging.config.file=logging.properties. To try different configurations you may use
-Dnet.finmath.montecarlo.opencl.RandomVariableOpenCL.deviceType=GPU -Dnet.finmath.montecarlo.opencl.RandomVariableOpenCL.deviceIndex=0-Dnet.finmath.montecarlo.opencl.RandomVariableOpenCL.deviceType=CPU -Dnet.finmath.montecarlo.opencl.RandomVariableOpenCL.deviceIndex=0-Dnet.finmath.montecarlo.opencl.RandomVariableOpenCL.deviceType=GPU -Dnet.finmath.montecarlo.opencl.RandomVariableOpenCL.deviceIndex=1
for example
mvn clean install test -Djava.util.logging.config.file=logging.properties -Dnet.finmath.montecarlo.opencl.RandomVariableOpenCL.deviceType=GPU -Dnet.finmath.montecarlo.opencl.RandomVariableOpenCL.deviceIndex=1
You may run dedicated tests using
-Dtest=RandomVariableGPUTest-Dtest=MonteCarloBlackScholesModelTest-Dtest=LIBORMarketModelCalibrationATMTest-Dtest=LIBORMarketModelCalibrationTest
The last tests are computationally heavy Monte-Carlo interest rate models. The test may fail on devices that lack sufficient memory.
Trying on Amazon EC2
If you do not have a machine with NVidia Cuda 10.0 at hand, you may try out the finmath-lib-cuda-extensions on an Amazon EC2 machine. To do so:
- Create an Amazon AWS account (if needed) an go to your AWS console.
- Select to start an EC2 virtual server.
- Launch a GPU instance
- Filter the list of images (AMI) using
gpuand select - e.g. -Deep Learning Base AMI (Ubuntu) Version 19.0. - Filter the list of servers using the “GPU instances” and select an instance.
- Login to your GPU instance.
- Check that you have cuda 10.0 (e.g. use
nvcc --version) - Try finmath-lib-cuda-extensions as described in the previous section.
Performance
Unit test for random number generation:
Running net.finmath.montecarlo.BrownianMotionTest Test of performance of BrownianMotionLazyInit ..........test took 49.057 sec. Test of performance of BrownianMotionJavaRandom ..........test took 65.558 sec. Test of performance of BrownianMotionCudaWithHostRandomVariable ..........test took 4.633 sec. Test of performance of BrownianMotionCudaWithRandomVariableCuda ..........test took 2.325 sec.
Unit test for Monte-Carlo simulation
Running net.finmath.montecarlo.assetderivativevaluation.MonteCarloBlackScholesModelTest BrownianMotionLazyInit calculation time = 4.00 sec value Monte-Carlo = 0.1898 value analytic = 0.1899. BrownianMotionJavaRandom calculation time = 5.19 sec value Monte-Carlo = 0.1901 value analytic = 0.1899 . BrownianMotionCudaWithHostRandomVariable calculation time = 2.50 sec value Monte-Carlo = 0.1898 value analytic = 0.1899. BrownianMotionCudaWithRandomVariableCuda calculation time = 0.09 sec value Monte-Carlo = 0.1898 value analytic = 0.1899 .
Remark: * BrownianMotionLazyInit: Calculation on CPU, using Mersenne Twister. * BrownianMotionJavaRandom: Calculation on CPU, using Java random number generator (LCG). * BrownianMotionCudaWithHostRandomVariable: Calculation on CPU and GPU: Random number generator on GPU, Simulation on CPU. * BrownianMotionCudaWithRandomVariableCuda: Calculation on GPU: Random number generator on GPU, Simulation on GPU.
Unit test for LIBOR Market Model calibration
There is also a unit test performing a brute force Monte-Carlo calibration of a LIBOR Market Model with stochastic volatility on the CPU and the GPU. Note however that the unit test uses a too small size for the number of simulation paths, such that the GPU code is no improvement over the CPU code. The unit test shows that CPU and GPU give consistent results.
The performance of a brute-force Monte-Carlo calibration with 80K and 160K paths are given below. Note: if the number of paths is increased, the GPU time remains almost the same (given that the GPU has sufficient memory), while the CPU time grows linearly. This is due to the fact that the GPU performance has a large part of fixed management overhead (which will be reduced in future versions).
The CPU version was run on a an Intel i7-7800X 3.5 GHz using multi-threadded calibration. THe GPU version was run on an nVidia GeForce GTX 1080.
LMM with 81,920 paths
Running net.finmath.montecarlo.interestrates.LIBORMarketModelCalibrationTest Calibration to Swaptions using CPU calculation time = 364.42 sec RMS Error.....: 0.198%. Calibration to Swaptions using GPU calculation time = 49.46 sec RMS Error.....: 0.198%.
(LIBOR Market Model with stochastic volatility, 6 factors, 81920 paths)
LMM with 163,840 paths
Running net.finmath.montecarlo.interestrates.LIBORMarketModelCalibrationTest Calibration to Swaptions using CPU calculation time = 719.33 sec RMS Error.....: 0.480%. Calibration to Swaptions using GPU calculation time = 51.70 sec RMS Error.....: 0.480%.
(LIBOR Market Model with stochastic volatility, 6 factors, 163840 paths)
Profiles for Other Cuda Versions
The default profile will build the version using Cuda 10.2.
Cuda 11.1
For Cuda 11.1 use
mvn -Pcuda-11.1 clean package
or
mvn -Dcuda.version=11.1 clean package
Cuda 11.0
For Cuda 11.0 use
mvn -Pcuda-11.0 clean package
or
mvn -Dcuda.version=11.0 clean package
Cuda 10.1
For Cuda 10.1 use
mvn -Pcuda-10.1 clean package
or
mvn -Dcuda.version=10.1 clean package
Cuda 10.0
For Cuda 10.0 use
mvn -Pcuda-10.0 clean package
or
mvn -Dcuda.version=10.0 clean package
Cuda 9.2
For Cuda 9.2 use
mvn -Pcuda-9.2 clean package
or
mvn -Dcuda.version=9.2 clean package
Cuda 8.0
For Cuda 8.0 use
mvn -P cuda-8.0 clean package
or
mvn -Dcuda.version=8.0 clean package
Cuda 6.0
For Cuda 6.0 use
mvn -P cuda-6.0 clean package
or
mvn -Dcuda.version=6.0 clean package
For Cuda 6.0 the jcuda binaries are not unpacked automatically and have to be installed manually. Set LD_LIBRARY_PATH (*nix environment variable) or java.library.path (Java system property) to the jcuda platform specific binaries.
References
- finmath lib Project documentation provides the documentation of the library api.
- finmath lib API documentation provides the documentation of the library api.
- finmath.net special topics cover some selected topics with demo spreadsheets and uml diagrams. Some topics come with additional documentations (technical papers).
License
The code of “finmath lib”, “finmath lib opencl extensions” and “finmath lib cuda extensions” (packages net.finmath.*) are distributed under the Apache License version 2.0, unless otherwise explicitly stated.